一般に公開されているWEBサイトの情報をアプリケーションに活用したい場合、
そのサイトがWebAPIを提供してくいれば何も問題がないのですが、大抵はHTMLで公開しているだけです。
よくある解決手段としては、HTML Parserを利用するか、正規表現を駆使して自前でHTML解析をする事になると思います。
さて、.NET FrameworkにはLINQ(統合言語クエリ)と呼ばれるフレームワークが存在し、
そのなかのLINQ to XMLという技術を利用することによりXMLを非常にスマートな形で扱うことができるようになります。
そこで今回は、SGMLReaderというライブラリを使い、
LINQ to XMLと組み合わせたスクレイピングについて紹介します。
所謂、LINQ to HTMLってヤツです。
まずは簡単な使い方を見ていただきましょう。
[csharp]
static void Main(string[] args)
{
XDocument xml;
using (var sgmlReader = new SgmlReader() { Href = "http://www.opentone.co.jp/" })
{
xml = XDocument.Load(sgmlReader);
}
// たったの3行でHTML to XMLが完了。後はLINQ to XMLで操作するだけ
var ns = xml.Root.Name.Namespace; // XML名前空間
foreach (var item in xml.Descendants(ns + "h4"))
{
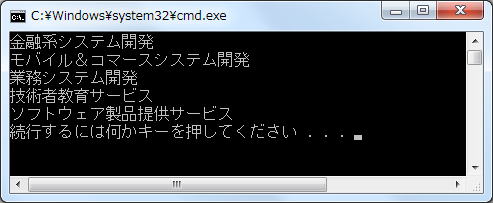
Console.WriteLine(item.Value); // OPENTONEのTOPページよりサービスを列挙
}
}
[/csharp]ご覧のとおり、非常に簡単です。
HtmlがXDocumentになってしまえば、後はLINQ to XMLの出番です。
例は、弊社(OPENTONE)のトップサイトにアクセスして、h4タグで囲まれたサービス情報を列挙しています。

続いて、より一般的なサイトから情報を取得してみましょう。
[csharp]
static void Main(string[] args)
{
XDocument xml;
using (var sgmlReader = new SgmlReader() { Href = "http://eki.jorudan.co.jp/unk/" })
{
xml = XDocument.Load(sgmlReader);
}
var ns = xml.Root.Name.Namespace;
var query = xml.Descendants(ns + "table")
.First(x => x.Attribute("class").Value.Equals("unktable"))
.Descendants(ns + "tr")
.Skip(1)
.Select(e => e.Elements(ns + "td").ToList())
.Select(info => new
{
Subject = info[1].Descendants(info[1].GetDefaultNamespace() + "strong").First().Value,
Description = info[2].FirstNode.ToString()
});
foreach (var item in query)
{
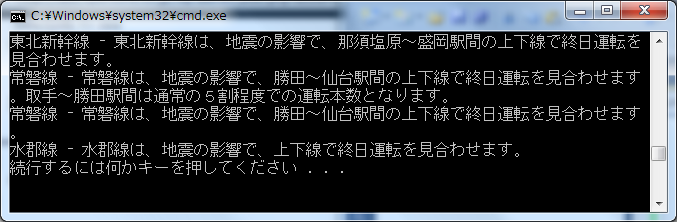
Console.WriteLine(item.Subject + " - " + item.Description);
}
}
[/csharp]上の例では、運行情報サービスの「ジョルダン」より、運行情報の列車名と状況を取得しています。
最近、計画停電の影響もあって鉄道運行状況が不安定ですし、よく訪問するんですよね。
WebAPIが公開されていないサイトでも、これなら簡単にスクレイピングが可能です。
元々HTMLなので抽出をするに適したXMLではないため、HTML Parserを利用した場合と同じく、目的の情報にたどり着くためには決め打ちの部分が入ってしまいますが、
LINQ to XMLという強力なXML文書処理が使えるのは大きなメリットだと思います。
是非、試してみてください。