皆さん、こんにちは。
前回、MySQLでテーブルを作成して、アナライズするところまで実施しましたので、
今回はEXPLAINを使って、クエリの実行計画を確認して行こうと思います。
まず、社員それぞれに関わっているプロジェクトを抽出するクエリで、EXPLAINを取ってみました。
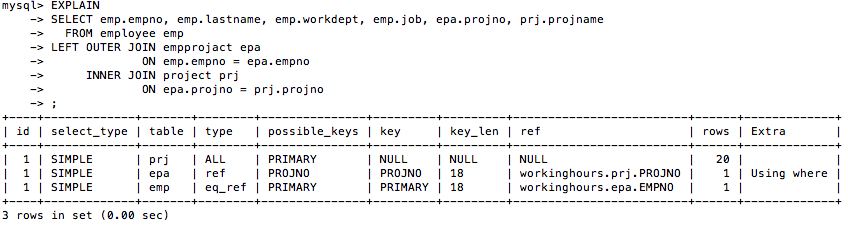
それぞれの項目は以下の内容を表しているようです。
(MySQLのサイトに記述されている情報だけでは理解しにくいため、若干意訳しています。)
EXPLAINの読み方
id:
おそらく、SUBQUERYが発行された場合の入れ子のレベルを表しているものと思われる。
クエリは、数字の少ないものから順に評価する。
select_type:
selectの種類。
実際には、発行したクエリのどのテーブルを取得するSQLかを
見分ける目印くらいの意味合いしかなさそう。
DEPENDENT UNIONやDEPENDENT SUBQUERYからは、
結合方法が読み取れるが、後述するtypeがあるからいらないような気もする。
table:
その処理がアクセスしているテーブル。
partitions:
partition構成のテーブルの場合に、その処理がアクセスしているpartitionを表す。
type:
結合型を表す。以下、それぞれの結合型の表す内容。
- system:
テーブルが1レコードのみで構成される場合、systemとなる。
systemはconstの特殊なパターンと見なせる。 - const:
指定した条件でテーブルから取得するレコードが1レコードのみとなる場合、
このレコードの値はオプティマイザによって定数と見なされ、
1回しか読み取られないため、高速。 - eq_ref:
Oracleで言う、nested loop joinに相当すると思われる。
外側のクエリで取得したレコード1レコードずつに対して、1レコードずつアクセスする。 - ref:
こちらは、nested loopでも、内側のクエリとの結合キーがuniqueではない場合に使用する結合形式。
当然、内側のクエリではキーに該当するレコードが全て取得される。 - ref_or_null:
refに加えて、結合キーの値がnullの場合の検索も実行される。 - index_merge:
複数のrenge scan結果を結合する場合に使われるらしい。 - unique_subquery:
サブクエリの返却する値が1レコードの場合に使用される。 - index_subquery:
サブクエリの返却する値が複数の場合に使用される。 - range:
インデックス範囲検索の場合に使用。 - index:
インデックスツリーに対する全件検索。Oracleで言う、index full scanに相当すると思われる。 - ALL:
全表検索。Oracleで言う、full scan。
オンライン処理のように、ある特定のレコードを取得してそのレコードを更新するような処理系であれば、
まずは”ALL”をなくすようにインデックスを利用するのが通常のチューニングになりますね。
ただ、MySQLのサイトから情報だけでは、Oracleと違って「それぞれの結合方式がどのくらいのコストを食うのか」あるいは、「どの様な問い合わせであれば、どの様な結合方式になれば効率が良さそうか」と言ったところが見えにくい。
次回は、EXPLAINで出力される残りの情報についての研究と、それぞれの結合処理の内容について調べてみたいと思います。
と言うわけで、次回に続く。