ビッグデータ活用による様々なビジネスモデルが検討、実践されている昨今。
日々増え続ける膨大なデータをどのように処理または整理したデータを、新たなビジネスにおける分析対象データとしてどのように有効活用するかが大きな命題となっています。
ビッグデータを活用するためのアーキテクチャが存在しアプローチの仕方も様々であるが、大きな問題のひとつとしてスキル不足であることがあげられ、これはシステムを依頼する側、作成する側の双方においてビッグデータの分析、活用のための人材不足が懸念されるているそうである。
なるほど・・・需要に供給が追い付いていない状況なのだな。
ならば弊社のメンバーが開発に携わっている「Hadoop」に関する引き合いも増えるのでは?
もうやっているよ!というツッコミが聞こえてきそうですが、今回はkoglenが自己学習した「Hadoop」についての特徴や周辺アーキテクチャについて紹介してみたいと思います。
「Hadoop」とは
「Hadoop」は大規模なデータを処理するための並列分散処理基盤であり、JavaをベースにIA(Intel Architecture)サーバーを利用して大量のデータを高速に処理できる。
用途としては、ログ解析やレコメンデーションエンジン、検索エンジンとして利用されることが多く、大きくは以下の2つのコンポーネントで構成されている。
- HDFS(Hadoop Distributed File System):分散ファイルシステム
- MapReduce(Hadoop MapReduce Framework):大規模分散処理FW
「Hadoop」の利用に適したデータ領域は、テラバイト、ペタバイトクラスのデータのバッチ処理にあたり、RDMSと比較するとその特徴が理解しやすいため以下に比較表を記載します。

上記のとおりデータを利用するうえでの特徴が異なるため、大量データの前段階の処理をHadoopで実施し、結果データに対してRDBMSによる参照管理とするのが望ましいようです。
さて「Hadoop」の大まかな特徴がわかったところで、事前に記載したメインコンポーネントについての説明も簡単に記載します。
HDFSについて
複数のサーバーで1つの巨大なファイルシステムを構成しており、以下のような特性があげられます。
- 巨大なファイルを使える
HDFSでは複数のDataNodoにつながる多くのHDDを束ねて使う仕組みが実現されている。しかし、数ある小さなファイルを管理するのには向いていない。
- シーケンシャルアクセスで高いスループットを出せる
HDFSではブロックサイズが大きく設計されており、大きなファイルにシーケンシャルにアクセスすることに最適化された作りになっている。
また、HDFSに一度格納されたファイルは呼び出すだけのアクセスパターンを想定しており更新はできず、ブロックサイズは設定ファイルの指定により変更が可能であるがDataNodoが使用するメモリは増加するため、デフォルトの64MBよりも128MBの方が多くの場合効率が良いという特徴がある。
- DataNodeの一部が故障しても、ファイルの損失を回避できる
レプリケーション、ラックアウェアネス、BackupNodeといった機能を持つことによりファイル損失を回避できる。
- 容量にスケーラビリティがある
スレーブノードであるDataNodeを追加することで、HDFSの容量を自由に拡張できる
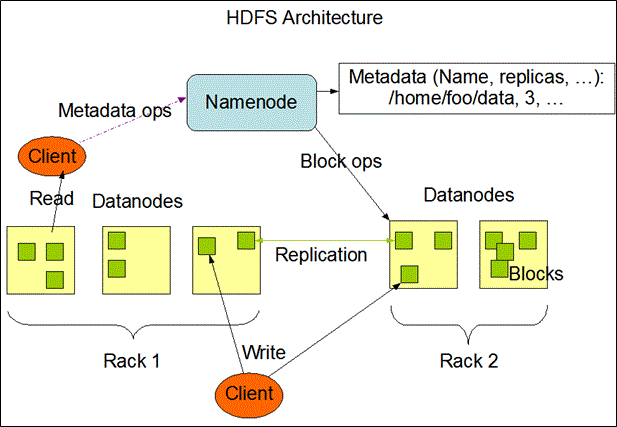
HDFSイメージと用語説明
DataNodo:固定長に区切られた「ブロック」という塊ごとにデータを管理する
NameNode:メタデータの管理、DataNodeの死活監視、HDFSの使用状況の確認などを管理する
MapReduceについて
Google社によって考案された分散処理アルゴリズムで大規模なデータを分散処理するのに都合の良いように、Map処理とReduce処理というフェーズに分けて整理される。
MapReduceは、データをKeyとValueの組み合わせで扱い、KeyとValueの値の組にして出力する処理をMap処理、Key値ごとにデータを集めて処理することをReduce処理という。
- Map処理:データから処理を元にKeyとValueの組を抽出する処理
- Reduce処理:抽出されたKeyとValueから目的の結果(KeyとValue)を得るための処理
「Hadoop」では、上記の処理をマスターサーバと多数のスレーブサーバの組み合わせで構成され以下のような特性があげられます。
- 高いスケーラビリティを持つ
Map処理やReduce処理は、処理対象のデータを分割することにより複数のワーカが同じ処理を並列に実行することができる。
Map、Reduceフェーズともにワーカの数を増やすことで簡単に高いスケーラビリティが実現できる。
- 処理の継続性が高い
1つのワーカに異常が発生して継続できなくなった場合でも、他のワーカに再度同じ処理を割り当てることができるため、全ての処理を最初から実施しなくても良い。
- データの局所性を考慮した処理コストの低減
Map処理は極力TaskTrackerと同じノードで起動しているHDFSのDataNodeのデータを利用しようとし、JobTrackerはHDFSのデータ局所性を考慮して同じノードのTraskTrackerに処理を割り当てるため、データのやり取りで発生する通信を抑え、ネットワーク帯域を節約したり、通信コストを抑えることができる。
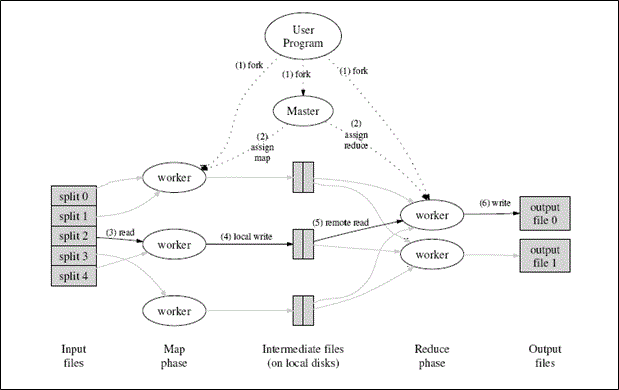
MapReduceイメージと用語説明
JobTracker:Hadoopのマスターノードであり、MapReduceFWが提供する分散処理を制御するためのマスターとして動作するJavaプロセス
TaskTracker:Hadoopのスレーブノードであり、TaskTrackerはHadoopのMapReduceFWの中で、Map処理およびReduce処理を実行するためのワーカとして動作する
これらが「Hadoop」を学習するうえでの基礎アーキテクチャ理解になるかと思います。
もちろんこれ以外にも引きつづき押さえておかなければならないHadoopエコシステムやディストリビューションなどがありますが、次回はローカルマシンに「Hadoop」環境を構築してみたいと思います。